
Training ChatGPT with Custom Libraries Using Extensions
David Giffin
April 24, 2023 · 6 min read
Enhance ChatGPT training with Release's dynamic environments for accurate AI model generation and testing.
Try Release for FreeI'm excited to share with you some of the fascinating work we've been doing here at Release. Our team has been exploring the power of embeddings, vector databases, and language models to create innovative product features. In this post, I'll explain our journey as we explored OpenAI and ChatGPT and how we are now leveraging embeddings and vector databases to generate prompts for ChatGPT.
We began to look into various ways to leverage AI in our product. We were hoping that we could have ChatGPT generate Release Application Templates, the blueprints that we use to describe an application in Release. We quickly realized that ChatGPT is only trained on data before September 2021 and it was questionable if it knew anything about Release.

Release supports using both Docker and Docker Compose so you would be able to use these files in Release to generate an Application Template. But it was clear that ChatGPT needed to be trained using the Release documentation or a large corpus Release Application Templates if it was going to generate one from scratch.
Exploring ChatGPT Plugins
ChatGPT Plugins seemed like the best way to give ChatGPT outside knowledge from its training set. We signed up for the ChatGPT Plugin waitlist and eventually got access to ChatGPT Plugins. The ChatGPT Retrieval Plugin seemed like a place to start experimenting with ChatGPT Plugins and get an understanding of how they work.
After adding a few files to the chatgpt-retrival-plugin we had it running Release. Then we started working on loading the data into the plugin, converting all of our docs into JSON and uploading them into the retrieval plugin using the `/upsert` endpoint. Once the plugin was configured ChatGPT we were able to ask ChatGPT to "How do I create an application template in Release"

The retrieval plugin works well for asking a question that can be answered using the documentation it has access to. However it was unclear when plug-ins are going to be generally available for all users to access. We plan to develop a ChatGPT Plugin that everyone can use once that happens.
Using Embeddings and Prompt Generation
As our team continued to explore the AI space we came across an article from the Supabase Blog. The article explained a different approach to "train" ChatGPT. Instead of ChatGPT having access to our documentation directly you could feed snippets of the docs to ChatGPT in the prompt. Here is the prompt template that takes the users question and the relevant snippets from the docs to answer a users question:
`
You are a very enthusiastic Release representative who loves
to help people! Given the following sections from the Release
documentation, answer the question using only that information,
outputted in markdown format. If you are unsure and the answer
is not explicitly written in the documentation, say
"Sorry, I don't know how to help with that."
Context sections:
${contextText}
x
"""
Answer as markdown (including related code snippets if available):
`
The folks who helped build the Supabase AI functionality also created an open source standalone project next.js OpenAI Search Starter. We have been using this project as a starting point for our AI based documentation search.
What are Embeddings?
Both the ChatGPT Retrieval Plugin and Supabase's AI Documentation Search rely on generating, storing and searching embeddings. So what is an embedding?
Embeddings are a way to represent text, images, or other types of data in a numerical format that can be easily processed by machine learning algorithms. In the context of natural language processing (NLP), word embeddings are vector representations of words, where each word is mapped to a fixed-size vector in a high-dimensional space. These vectors capture the semantic and syntactic relationships between words, allowing us to perform mathematical operations on them. The following diagram shows the relationship between various sentences:

image of sentence embeddings - from DeepAI
Embeddings can be used to find words that are semantically similar to a given word. By calculating the cosine similarity between the vectors of two words, we can determine how similar their meanings are. This is a powerful tool for tasks such as text classification, sentiment analysis, and language translation.
What are Vector Databases?
Vector databases, also known as vector search engines, are specialized databases designed to store and search for high-dimensional vectors efficiently. They enable fast similarity search and nearest neighbor search, which are essential operations when working with embeddings.
Supabase's AI Documentation Search uses pgvector to store and retrieve embeddings. But many other vector databases exist today:
Pinecone, a fully managed vector database
Weaviate, an open-source vector search engine
Redis, a vector database
Qdrant, a vector search engine
Milvus, a vector database built for scalable similarity search
Chroma, an open-source embeddings store
Typesense, fast open source vector search
All of these databases support three basic things: storing embeddings as vectors, the ability to search the embedding/vectors and finally sorting the results based on similarity. When using OpenAI's `text-embedding-ada-002` model to generate embeddings OpenAI recommends using cosine similarity which is built into most of the vector databases listed above.
How to Generate, Store and Search Embeddings
OpenAI provides an API endpoint to generate embeddings from any text string.
```ruby
# OpenAI recommends replacing newlines with spaces
# for best results (specific to embeddings)
input = section.gsub(/\n/m, ' ')
response = openai.embeddings(parameters: { input: input, model: "text-embedding-ada-002"})
token_count = response['usage']['total_tokens'] # number of tokens used
embedding = response['data'].first['embedding'] # array of 1536 floats
Storing this data in Redis [redis-stack-server](https://redis.io/docs/stack/) and making it searchable requires an index. To create an index using redis-stack-server you need to issue the following command:
```ruby
FT.CREATE index ON JSON PREFIX 1 item: SCHEMA $.id AS id TEXT $.content AS content TEXT $.token_count AS token_count NUMERIC $.embedding AS embedding VECTOR FLAT 6 DIM 1536 DISTANCE_METRIC COSINE TYPE FLOAT64
Now we can store items into Redis and havethem indexed with the following command:
{
"id": "963a2117895ec9a29f242f906fd188c6",
"content": "# App Imports: …",
"embedding": [0.008565563, 0.012807296]
}
Note that if you don't provide all 1536 dimensions of the vector your data will not be indexed by Redis and it will give you no error response.
Searching Redis for results and sorting them can be done with the following command:
```redis
FT.SEARCH index @embedding:[VECTOR_RANGE $r $BLOB]=>{$YIELD_DISTANCE_AS: my_scores} \
PARAMS 4 BLOB \x00\x00\x00 r 5 LIMIT 0 10 SORTBY my_scores DIALECT 2
Note that BLOB provided is in binary format and needs to have all 1536 dimensions of vector data as well. We use the OpenAI Embeddings API to generate the embedding vector and convert it to a binary in Ruby using \`embedding.pack("E\*")\`.
### Release ChatGPT Powered Documentation Search
We have replaced the backend [next.js OpenAI Search Starter](https://github.com/supabase-community/nextjs-openai-doc-search) with Ruby and Redis. We will be releasing our project as an open source Gem that will allow anyone to quickly add AI based document searching to their site.
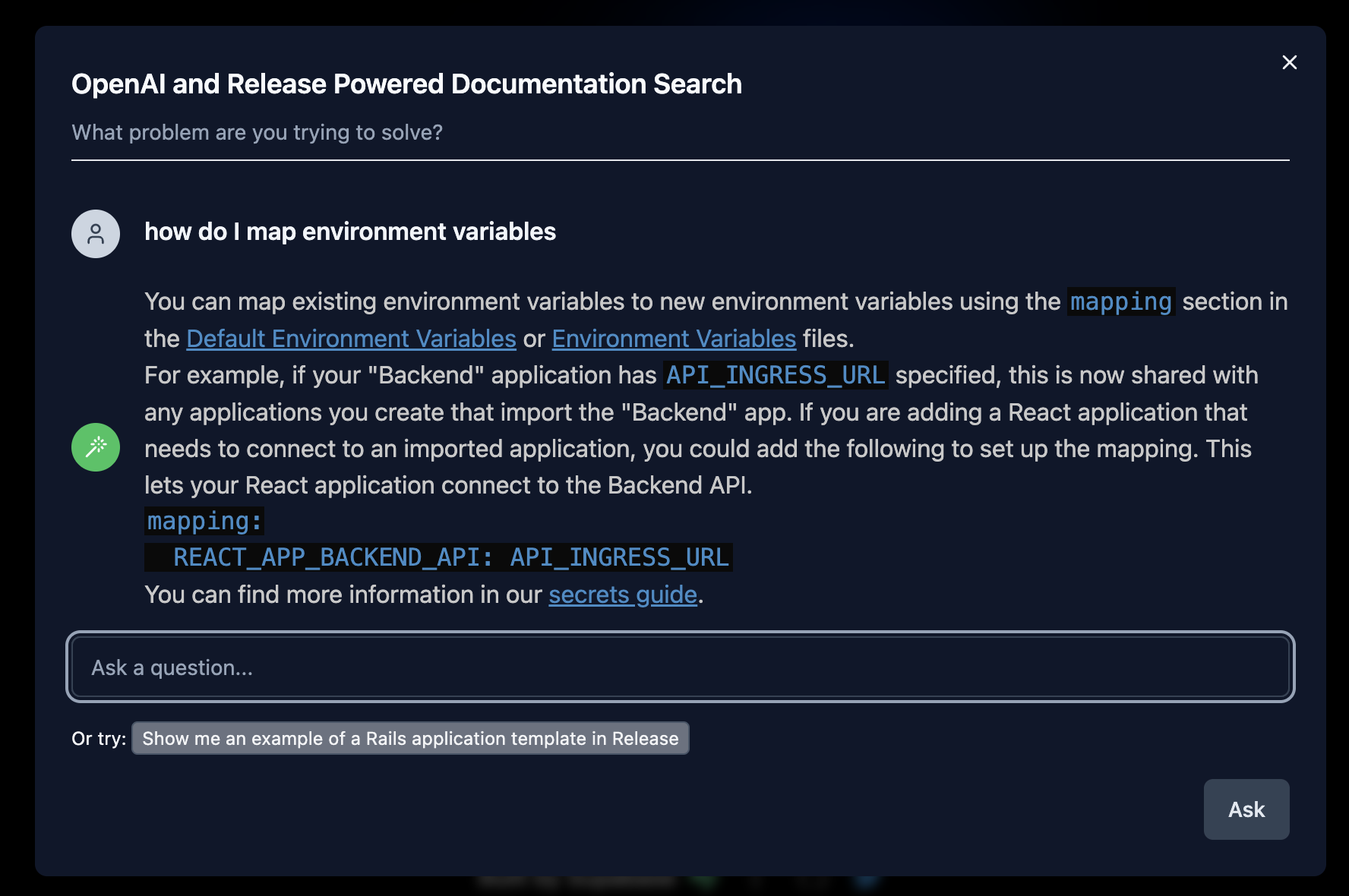
We have a [working example](https://frontend-vapey-prod.releaseapp.gethandsup.com/) of the Release AI Powered Documentation Search using slightly modified version of the [next.js OpenAI Search Starter.](https://github.com/supabase-community/nextjs-openai-doc-search\)) We've added support for scrolling, better rendering of markdown (which the Supabase version had) and the ability to plugin your search API backend.
### Conclusion
By combining the power of embeddings, vector databases, and language models like ChatGPT, we've been able to create product features that provide valuable insights and enhance user experiences. Whether it's answering customer queries, generating personalized content, or providing recommendations, our approach has opened up new possibilities for innovation.
We're excited about the potential of this technology, and we're looking forward to exploring new ways to leverage it in the future. As we continue to develop and refine our product offerings, we're committed to staying at the forefront of AI and NLP research. Our goal is to create tools and solutions that empower businesses and individuals to harness the power of language models in meaningful and impactful ways.
Thank you for taking the time to read our blog post. We hope you found it informative and that it sparked your curiosity about the exciting possibilities that embeddings, vector databases, and language models like ChatGPT have to offer. If you have any questions or would like to learn more about our work at Release, [please feel free to reach out to us or book a demo.](https://release.com/book-a-demo) We'd love to hear from you!
Enhance ChatGPT training with Release's dynamic environments for accurate AI model generation and testing.
Try Release for Free